The Dreaded "Scalable" Word
One of my pet hates is the way the word "scalable" is bandied around within the IT industry, as if it were some sort of must-have fashion accessory. Managers, developers, architects, and project managers, all throw the word into a conversation, as one of the 'essential' requirements of a system, and then everyone proceeds to nod their heads in knowing agreement, as if they would be seen to be ignorant in some way if they at all questioned it - either the meaning or the need.
What It Means
My first problem with the word "scalable" is that most of the time it is used without the user even being aware of what it actually means. Wikipedia, citing a definition from another source[1], describes scalability as being "a desirable property of a system, a network, or a process, which indicates its ability to either handle growing amounts of work in a graceful manner, or to be readily enlarged." That sounds great, but how does that translate in the real world?
Well, imagine that we have some sort of "system" - this could be any sort of system: anything from an application to handle withdrawals from cash machines (ATMs), to a billing system for a telecoms company. Taking the first example, suppose our system can handle 1000 withdrawals per minute. If the system were scalable, then it would be possible to increase the number of withdrawals per minute that it can handle, simply by increasing a "resource". There are many things that can be considered a resource (and more on that below), but the usual ones are: memory, the number of processors (CPUs), network bandwidth etc.
If the cash machine system were perfectly scalable, it would be possible to double the number of withdrawals per minute simply by doubling one or more resources; this might be the number of processors, for example. It would be great to double the number of withdrawals that the system can manage to 2000 per minute, simply by adding another CPU to the central computer, or to 3000 per minute by adding two extra CPUs.
Why would anyone want to be able to do this? There are a number of reasons why a scalable system might be desirable; here are a couple of them:
- It allows the up-front capital investment to be reduced - spreading costs over a period of time. It is unlikely that the full capacity will be required from day one, so the additional resources can be purchased later as the volume builds up.
- It lets the system architect to be fairly uncertain about what the capacity of a system should be, and allows the resources to be allocated as necessary to match the demand.
So now that we have an idea of what it means, what are my other issues with the word "scalable"? Well the second and third issues are related: many people don't understand exactly what is involved with building a scalable system, and in fact they don't actually need such a system - what they actually want is a system that is fast enough.
A Simple System
To illustrate these two points, let's look at some very basic theory - a grossly simplified conceptual "system". The system consists of a load balancer, which splits incoming work packets between one or more processing units, and these actually do the work. For the purposes of this discussion, it doesn't really matter what the work packets are, just think of them as representing some abstract unit of work.
Each processing unit can process a maximum of 1000 work packets per minute.
Figure 1: A simple system
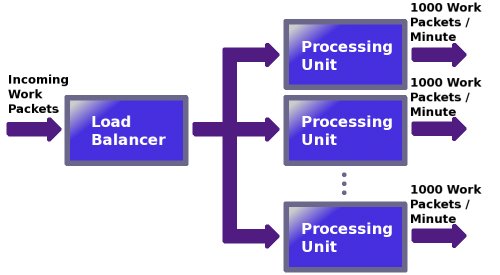
If the system were perfectly scalable, then we could simply add more processing units as required, to match our workload: 1 processing unit = 1000 work packets / minute, 2 processing units = 2000 work packets / minute, 3 processing units = 3000 work packets / minute, and so on.
Unfortunately, as I'm sure you've spotted, there is a problem with this nice simple scalable system, and that is the load balancer. For this system to be perfectly scalable forever, the load balancer would need to be able to handle an infinite number of work packets per minute. I don't know about you, but if I had invented such a component, then I would be very rich, and currently not one bit interested in scalable systems, but instead sipping cocktails on a beach somewhere in the Caribbean!
Shared Resources
The load balancer, which is shared between the processing units, will limit the number of work packets that our system can handle, regardless of how many processing units we add. In the real world, we wouldn't even have the luxury of a linear increase in work units processed for each processing unit. In fact we may only increase the performance by 50%. The reason this happens in normal systems is that there is usually some contention over the shared resource (the load balancer) by the scaling resources (the processing units); the load balancer won't be able to deal with three processing units as efficiently as it can deal with two, for example. The actual proportional increase in performance that we get is a measure of how well our system scales.
Eventually we come to a point where we get diminishing returns: we find that adding another processing unit yields so little performance improvement that it is simply not worth the cost. Indeed, we may even get to the point where adding resources actually makes the overall performance worse, simply because there is so much contention.
"Ah", we hear you cry. "Why not increase the number of load balancers as well?" Unfortunately, all that does is move the problem up the chain. There is always a shared resource. In fact, if there were no shared resource, it wouldn't be a single system at all. There are lots of resources that may be shared in any system; here are a few examples:
- Processing time (CPU cycles)
- System buses
- Memory
- The Operating System
- Permanent storage: discs, storage area networks (SANs) etc.
- Networks: Local Area Networks (LANs), Wide Area Networks (WANs), and even the Internet itself!
So, what can we do about it? Well it should be easy to see that if the shared resources are placing an upper limit on the capacity of our system, then it's those we need to concentrate on. So going back to our example, if we want our system to scale up to 10,000 work packets a minute, then we need to make sure that our load balancer can handle that amount of work.
But hang on a second. Can you see what we've just done? We've now set an upper-limit on the performance of our system, at 10,000 work packets a minute. Wasn't the whole point of a scalable system that we didn't want to do that? Therein lies the problem, and you can probably now see why I hate it when people use the word "scalable" without thinking about it. The 'architect' of the system has placed a limit on the capacity of their system, whether they intended to or not.
I use the term "architect" loosely here, because those of you who have worked in IT for a while will know that quite often these sorts of decisions are not always made by a technically proficient architect, but quite often by those who do not appreciate their implications: managers, project managers, or even non-technical business users. Don't even get me started about how very few projects even test whether their system can actually handle the full load that has been predicted, or that most of these predictions are little better than if they had simply thrown a dart at a series of numbers on a piece of paper.
Summary
Even if systems are built with scalability in mind, few people bother to test whether their systems scale as intended. Wouldn't it just be a better idea to make the system fast enough? If you know that your upper limit is going to be 10,000 work packets per minute, why not just drop any pretence that the system has been or will be designed to be scalable, and just aim for the full capacity - develop a "processing unit" that can handle 10,000 work packets per minute?
Building truly scalable systems is hard. In many cases it is far easier just to build components that are fast enough to begin with than to build components that scale.
The next time you're in a design meeting, and someone mentions that a system needs to be scalable, ask them what they actually mean, and then question whether it's really what they want.