Indexes Are All Around Us (Part 1)
OK, so it won't make it onto the soundtrack of a Richard Curtis film any time soon, but the fact is that we use indexes every day. Indexes actually are all around.
In fact, there are two common types of index that we are all familiar with using. The beauty of them is that they have direct equivalents within the relational database world, so understanding why they are useful can also help us to understand why database indexing is so important.
Don't You Mean Indices?
But first, before I go into all of that, you're probably wondering why I've used the word "indexes" rather than "indices". Or perhaps you're not. In any case, I'm going to tell you regardless. For some unknown reason (well, it's unknown to me at least), it seems to have become a convention that most people in the industry refer to the plural of a database index as "indexes". The other word - "indices" is used more for things like stock market indices. The dictionary seems to list both as being an acceptable plural version, so let's just put it down to convention.
Find Me A Number
Let's start by looking at something we are quite familiar with: a telephone directory.
Sturnusville is a small town in Sturnushire. (It isn't - I just made it up, so please don't look it up and then complain to me that you can't find it!). Rather conveniently there are exactly 10,000 inhabitants. The Sturnusville telephone directory lists all the inhabitants, their addresses, and their telephone numbers, just as normal directories do. Each page can hold 50 entries, so there are 200 pages in total.
If I handed you the directory and asked you to find the number for Donald Sedgwick, living at 34 Jade Crescent, how would you do it? Would it be easy or difficult? Hopefully (unless you've never used a telephone directory in your life), you would find it pretty easy. Like all good directories it's in alphabetical order by surname (family name), and each page has a range of surnames marked at the top, so to find the number you wanted, you would probably do something like this:
- Flick backwards and forwards through the pages until you found one marked "Scott - Sellers". Your method of flicking backwards and forwards would probably involve starting somewhere in the middle; determining if the page you wanted was before or after the one you found, and then estimating how many pages you needed to skip to get closer to the one you want.
- Once you had found the correct page, you would scan down the entries until you found the first Sedgwick. Then you would read down the list of Sedgwicks until you found one called Donald that lived at 34 Jade Crescent, and hey presto: the number is 709 137.
Figure 1: Page 160 of the Sturnusville telephone directory
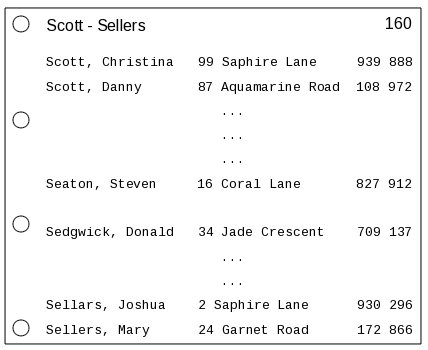
That was pretty simple wasn't it?
Now tell me who has the number 919 074.
Unfortunately the directory makes it easy to find numbers when we know the surname, first name, and address, but no easier at all if we only have a number. In fact, we would have to search through every page (all 200 of them) by hand, looking at every entry until we found the correct one. So why is this? What makes the directory useful for one particular type of search but not for others?
What Makes It Useful?
Before I answer that, let me give you a few more things to find. Have a think about which of these should be easy, and which should be hard:
- The number for Amy Savage
- The number for the Cunningham family, living somewhere on Turquoise Close
- The address of Danny Lindsell
- The number for Antonio, who lives at 66 Coral Road
- The number for someone whose surname begins with "Ban", living at 41 Emerald Lane
Obviously the more information that we are provided with, the better. But it is obvious that the piece of information that makes the biggest difference to the difficulty of the search is the surname. If we know the surname, the search is always much easier than if we don't. In fact, if we don't know the surname, we always have to look through all 10,000 entries in the directory.
What's more, if we also know the first name, then the search is even easier. Indeed, in most cases there will only be one person with a particular surname and first name, so we can find addresses as well as numbers. In fact, the search gets easier as we know the following information (make particular note of the order):
- Surname
- Surname + first name
- Surname + first name + address
What may be surprising, however, is the last search listed above: even if we only know part of the surname, we can still find the correct entry relatively easily. The important thing to remember though, is that to be useful, we need to know the beginning of the surname. If I ask you for entries where the name ends with "ton", it's back to going through every entry in the directory one at a time.
So let's rewrite the list to include partial information:
- Start of surname
- Whole surname
- Whole surname + start of first name
- Whole surname + whole first name
- Whole surname + whole first name + start of address
- Whole surname + whole first name + whole of address
It is obviously no coincidence that the amount of information I need to reduce the search space (and hence the effort I expend in performing my search) matches exactly with the way that the directory is ordered (or sorted): first on surname, then on first name, then on address. In the database world, these are known as the key; more accurately, this is a composite key because it does not just contain one piece of information - it is composed of the surname AND the first name AND the address.
The fact that the data is sorted in key order is part of what makes the index useful. Hang on a second... where did the index suddenly come from? What index? Well in this case the index is rather subtle: remember the "Scott - Sellers" label on the top of page 160? These tags, combined with the ordering of the data, are what gives us our index.
Search Space vs. Matches
I want to digress briefly, just to talk about the difference between search space and the number of matches. You may be wondering why I'm making such a fuss about needing the start of the index key, since if we know the surname and address, and there is only one match, surely that is good enough?
The size of the search space determines the amount of effort that needs to be expended to find the matches. The number of matches is the number of entries in my directory that match my search criteria. I can illustrate this quite easily with a couple of examples:
- I'm looking for the number for Russell Begum, of 22 Jade Crescent. Unfortunately there is no Russell Begum at this address, there is only one living at 43 Emerald Crescent. My search criteria is that the surname is "Begum", the first name is "Russell", and the address is "22 Jade Crescent"; my search space is actually 0, because we have the entire key - the surname, first name, and address, but there is no matching entry, i.e. the number of matches is 0.
- I'm looking for anyone with the number 122 278. There is only one person with this number: Jack Woodward, of 24 Amethyst Road, but I have to search the entire telephone directory to find him. So my search criteria is that the number is "122 278"; my search space is the whole directory - all 10,000 entries; and the number of matches is 1.
Figure 2: Searching for "Berry" at "22 Sapphire Crescent"
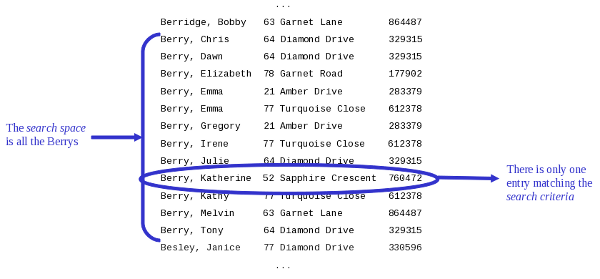
Knowing part of the key only helps to reduce the search space (and hence the effort) if it is the beginning part that we know, regardless of how many matches there are. In computer terms, reducing the search space is crucial. The smaller the search space, the less effort is required to find the results we are looking for. Less effort means better performance, and the result will be that your database query takes less time to run.
Clustered Index
The layout of the telephone directory is very similar to a type of database index known as a clustered index (sometimes also referred to as an index only table). Obviously there are differences - computers don't "flick" backwards and forwards randomly looking for the correct page. Also, the telephone directory only lists the surname at the top of each page - so the index does not incorporate the whole key. In forthcoming articles I shall explore these differences in more detail, but for now the analogy is useful.
The word "clustered" is used because entries (or rows) with similar key values are clustered together - all the Smiths are together, all the Wilsons are together etc. I know, it's a bit tenuous, but let's face it, bad naming conventions are the bane of the IT industry. A better description would probably be something like "unified index and key ordered table", because quite literally the data is sorted in the same order as the index key, but that's more of a mouthful than "clustered index".
Let me summarise what we know about this type of index. For those of you who are eager to see how this translates into the database world, I'll also use the formal terminology along side. Don't worry if you don't understand the descriptions on the right at this point, they mean exactly the same as the left but just in database-speak:
| The more we know of the surname, the first name, and the address (in that order), the less effort that we need to expend searching for entries we are interested in. | The more we know of the index key, in a contiguous chunk from the first byte of the first column, the fewer rows we need to scan to find those matching our search criteria. |
| If we don't know the start or all of the surname, we always have to go through every entry in the directory. | If we don't know the start of the index key, then we always have to perform a table scan. |
So that's the first type of index that we commonly use day-to-day. In Part 2, I will introduce the second type of index, which should be even more familiar.